Translation with a Sequence to Sequence Network and Attention (Urdu to English)
In this blog I will be teaching a neural network to translate from English to Urdu by using PyTorch library. All code and data set are available on the GitHub repository.

The Sequence to Sequence model
A Sequence to Sequence network, or seq2seq network, or Encoder Decoder network, is a model consisting of two separate RNNs called the encoder and decoder. The encoder reads an input sequence one item at a time, and outputs a vector at each step. The final output of the encoder is kept as the context vector. The decoder uses this context vector to produce a sequence of outputs one step at a time.

When using a single RNN, there is a one-to-one relationship between inputs and outputs. We would quickly run into problems with different sequence orders and lengths that are common during translation. Consider the simple sentence “Je ne suis pas le chat noir” → “I am not the black cat”. Many of the words have a pretty direct translation, like “chat” → “cat”. However the differing grammars cause words to be in different orders, e.g. “chat noir” and “black cat”. There is also the “ne … pas” → “not” construction that makes the two sentences have different lengths.
With the seq2seq model, by encoding many inputs into one vector, and decoding from one vector into many outputs, we are freed from the constraints of sequence order and length. The encoded sequence is represented by a single vector, a single point in some N dimensional space of sequences. In an ideal case, this point can be considered the “meaning” of the sequence.
The Attention Mechanism
The fixed-length vector carries the burden of encoding the the entire “meaning” of the input sequence, no matter how long that may be. With all the variance in language, this is a very hard problem. Imagine two nearly identical sentences, twenty words long, with only one word different. Both the encoders and decoders must be nuanced enough to represent that change as a very slightly different point in space.
The attention mechanism addresses this by giving the decoder a way to “pay attention” to parts of the input, rather than relying on a single vector. For every step the decoder can select a different part of the input sentence to consider.

Attention is calculated with another feedforward layer in the decoder. This layer will use the current input and hidden state to create a new vector, which is the same size as the input sequence (in practice, a fixed maximum length). This vector is processed through softmax to create attention weights, which are multiplied by the encoders’ outputs to create a new context vector, which is then used to predict the next output.

Implementation
Following are steps for predict sequence from the previous sequence with PyTorch.
Requirements
You will need PyTorch to build and train the models, and matplotlib for plotting training and visualizing attention outputs later.
Here we will also define a constant to decide whether to use the GPU (with CUDA specifically) or the CPU. If you don’t have a GPU, set this to False. Later when we create tensors, this variable will be used to decide whether we keep them on CPU or move them to GPU.
Loading our Data
For our dataset, you will use a dataset from Tab-delimited Bilingual Sentence Pairs. Here I will use the English to Urdu dataset. You can choose anything you like but remember to change the file name and directory in the code. The file is a tab separated list of translation pairs:
We won. ہم جیت گئےSimilar to the character encoding used in the character-level RNN tutorials, we will be representing each word in a language as a one-hot vector, or giant vector of zeros except for a single one (at the index of the word). Compared to the dozens of characters that might exist in a language, there are many many more words, so the encoding vector is much larger. We will however cheat a bit and trim the data to only use a few thousand words per language.

Data Preparation
You can’t use the dataset directly. You need to split the sentences into words and convert it into One-Hot Vector. Every word will be uniquely indexed in the Lang class to make a dictionary. The Lang Class will store every sentence and split it word by word with the addSentence. Then create a dictionary by indexing every unknown word for Sequence to sequence models.
For every sentence that you have,
- you will normalize it to lower case,
- remove all non-character
- convert to ASCII from Unicode
- split the sentences, so you have each word in it.
To read the data file we will split the file into lines, and then split lines into pairs. The files are all English → Other Language, so if we want to translate from Other Language → English I added the reverse flag to reverse the pairs.
Since there are a lot of example sentences and we want to train something quickly, we’ll trim the data set to only relatively short and simple sentences. Here the maximum length is 30 words.
The full process for preparing the data is:
- Read text file and split into lines, split lines into pairs
- Normalize text, filter by length and content
- Make word lists from sentences in pairs
Output of above snippet of code:
Reading lines...
lines read successfully
Read 1146 sentence pairs Trimmed to 1146 sentence pairs
Counting words...
Counted words:
urdu 1738
eng 1400
['تمھارے گھر والے کیسے ہے؟', "how's it going with your family ?"]The Seq2Seq Model
A Recurrent Neural Network, or RNN, is a network that operates on a sequence and uses its own output as input for subsequent steps.
A Sequence to Sequence network, or seq2seq network, or Encoder Decoder network, is a model consisting of two RNNs called the encoder and decoder. The encoder reads an input sequence and outputs a single vector, and the decoder reads that vector to produce an output sequence.
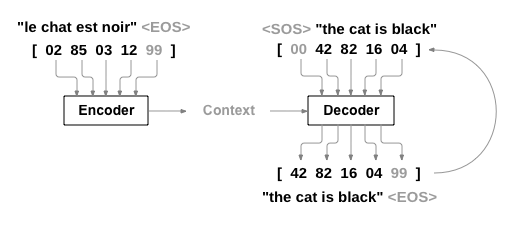
Unlike sequence prediction with a single RNN, where every input corresponds to an output, the seq2seq model frees us from sequence length and order, which makes it ideal for translation between two languages.
With a seq2seq model the encoder creates a single vector which, in the ideal case, encodes the “meaning” of the input sequence into a single vector — a single point in some N dimensional space of sentences.
The Encoder
The encoder of a seq2seq network is a RNN that outputs some value for every word from the input sentence. For every input word the encoder outputs a vector and a hidden state, and uses the hidden state for the next input word.
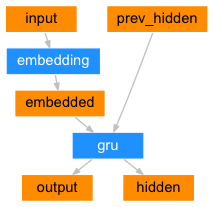
The Decoder
The decoder is another RNN that takes the encoder output vector(s) and outputs a sequence of words to create the translation.
Simple Decoder
In the simplest seq2seq decoder we use only last output of the encoder. This last output is sometimes called the context vector as it encodes context from the entire sequence. This context vector is used as the initial hidden state of the decoder.
At every step of decoding, the decoder is given an input token and hidden state. The initial input token is the start-of-string <SOS> token, and the first hidden state is the context vector (the encoder’s last hidden state).
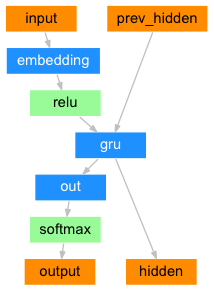
I encourage you to train and observe the results of this model, but to save space we’ll be going straight for the gold and introducing the Attention Mechanism.
Attention Decoder
If only the context vector is passed between the encoder and decoder, that single vector carries the burden of encoding the entire sentence.
Attention allows the decoder network to “focus” on a different part of the encoder’s outputs for every step of the decoder’s own outputs. First we calculate a set of attention weights. These will be multiplied by the encoder output vectors to create a weighted combination. The result (called attn_applied in the code) should contain information about that specific part of the input sequence, and thus help the decoder choose the right output words.
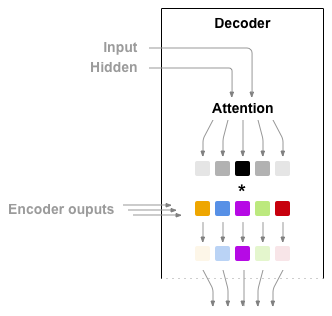
Calculating the attention weights is done with another feed-forward layer attn, using the decoder’s input and hidden state as inputs. Because there are sentences of all sizes in the training data, to actually create and train this layer we have to choose a maximum sentence length (input length, for encoder outputs) that it can apply to. Sentences of the maximum length will use all the attention weights, while shorter sentences will only use the first few.
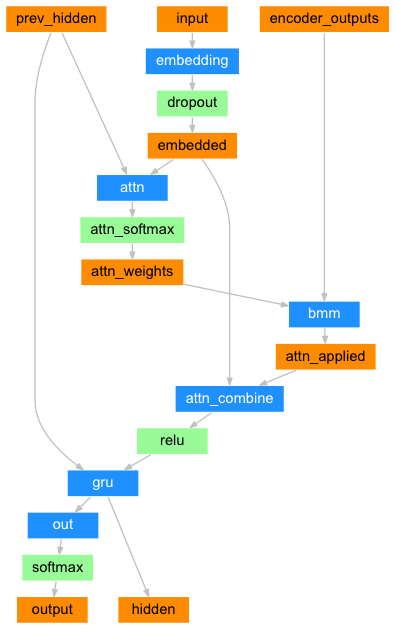
Training
Preparing Training Data
To train, for each pair we will need an input tensor (indexes of the words in the input sentence) and target tensor (indexes of the words in the target sentence). While creating these vectors we will append the EOS token to both sequences.
Training the Model
To train we run the input sentence through the encoder, and keep track of every output and the latest hidden state. Then the decoder is given the <SOS> token as its first input, and the last hidden state of the encoder as its first hidden state.
“Teacher forcing” is the concept of using the real target outputs as each next input, instead of using the decoder’s guess as the next input. Using teacher forcing causes it to converge faster but when the trained network is exploited, it may exhibit instability.
You can observe outputs of teacher-forced networks that read with coherent grammar but wander far from the correct translation — intuitively it has learned to represent the output grammar and can “pick up” the meaning once the teacher tells it the first few words, but it has not properly learned how to create the sentence from the translation in the first place.
Because of the freedom PyTorch’s autograd gives us, we can randomly choose to use teacher forcing or not with a simple if statement. Turn teacher_forcing_ratio up to use more of it.
This is a helper function to print time elapsed and estimated time remaining given the current time and progress %.
The whole training process looks like this:
- Start a timer
- Initialize optimizers and criterion
- Create set of training pairs
- Start empty losses array for plotting
Then we call train many times and occasionally print the progress (% of examples, time so far, estimated time) and average loss.
Plotting results
Plotting is done with matplotlib, using the array of loss values plot_losses saved while training.
Evaluation
Evaluation is mostly the same as training, but there are no targets so we simply feed the decoder’s predictions back to itself for each step. Every time it predicts a word we add it to the output string, and if it predicts the EOS token we stop there. We also store the decoder’s attention outputs for display later.
We can evaluate random sentences from the training set and print out the input, target, and output to make some subjective quality judgements:
Training and Evaluating
With all these helper functions in place (it looks like extra work, but it makes it easier to run multiple experiments) we can actually initialize a network and start training.
Remember that the input sentences were heavily filtered. For this small dataset we can use relatively small networks of 256 hidden nodes and a single GRU layer.
1m 14s (- 17m 28s) (5000 6%) 3.9061
2m 29s (- 16m 13s) (10000 13%) 2.4662
3m 45s (- 15m 3s) (15000 20%) 1.1312
5m 3s (- 13m 54s) (20000 26%) 0.3963
6m 20s (- 12m 41s) (25000 33%) 0.1164
7m 39s (- 11m 28s) (30000 40%) 0.0605
8m 57s (- 10m 13s) (35000 46%) 0.0441
10m 14s (- 8m 57s) (40000 53%) 0.0408
11m 32s (- 7m 41s) (45000 60%) 0.0305
12m 48s (- 6m 24s) (50000 66%) 0.0314
14m 6s (- 5m 7s) (55000 73%) 0.0248
15m 24s (- 3m 51s) (60000 80%) 0.0267
16m 42s (- 2m 34s) (65000 86%) 0.0251
18m 0s (- 1m 17s) (70000 93%) 0.0201
19m 17s (- 0m 0s) (75000 100%) 0.0221> سلام۔
= hi .
< hi . <EOS>
> میں نے ٹام کا کافی دیر تک انتظار کیا۔
= i waited for tom for a long time .
< i waited for tom for a long time . <EOS>
> یہ گھر ایک ہفتہ بعد ہی گر گیا۔
= the house fell down one week later .
< the house fell down one week later . <EOS>
> میرے خیال میں کويی دوست نہ ہونا بہت دکھ کی بات ہے ۔
= i think it's sad to not have any friends .
< i think it's sad to not have any friends . <EOS>
> وہ اور صرف وہ ہی پوری سچايی جانتا ہے۔
= he and only he knows the whole truth .
< he and only he knows the whole truth . <EOS>
> قیامت ا چکی ہے۔
= the day of judgment has arrived .
< the day of judgment has arrived . <EOS>
> ٹام اس ریستوران میں تب سے جا رہا ہے جب سے وہ نوجوان ہوتا تھا۔
= tom has been eating at that restaurant since he was a teenager .
< tom has been eating at that restaurant since he was a teenager <EOS>
> کھانے سے پہلے ہمیشہ ہاتھ دھویا کرو۔
= you should always wash your hands before meals .
< you should always wash your hands before meals . <EOS>
> اس کا مطلب کیا ہو سکتا ہے؟
= what could he mean ?
< what could he mean ? <EOS>
> ممکن ہے کہ وہ اجايے گی۔
= she'll probably come .
< she'll probably come . <EOS>
Conclusion
All code and data set are available on the GitHub repository. Same NMT code implemented in Keras in following blog.